 Mediante el uso de POedit, uno puedo crear traducciones para internacionalización sobre un archivo base, el cuál contiene las cadenas de texto de cierto software. Sin embargo si las cadenas son muchas, podemos hacer uso de alguna herramienta de traducción, y limitarnos a luego revisar y encontrar la traducción más adecuada para el contexto en el que se encuentra cada texto.
Mediante el uso de POedit, uno puedo crear traducciones para internacionalización sobre un archivo base, el cuál contiene las cadenas de texto de cierto software. Sin embargo si las cadenas son muchas, podemos hacer uso de alguna herramienta de traducción, y limitarnos a luego revisar y encontrar la traducción más adecuada para el contexto en el que se encuentra cada texto.
Particularmente necesitaba traducir un tema de WordPress que traía su propio archivo .po en inglés (en-EN.po). Hice un pequeño script en Python que hace uso de py-translate. Este módulo hace uso de la API de Google Translate. Quizá a alguno le resulte útil o pueda adaptarlo a sus necesidades (ya que está todo harcodeado dentro :-P).
# coding=utf-8
import gtrans
fo = open("en_EN.po","r")
fi = open("es_ES.po","w")
for line in fo:
if line.find("msgid") == 0:
cad = gtrans.translate("en","es",line.split("\"")[1])
#print line.encode("utf-8"),
fi.write(line.encode("utf-8"))
fi.write("msgstr \""+cad.rstrip().encode("utf-8")+"\"\n")
elif line.find("msgstr") == 0:
pass
else:
#print line.encode("utf-8"),
fi.write(line.encode("utf-8"))
fo.close()
fi.close() |
# coding=utf-8
import gtrans
fo = open("en_EN.po","r")
fi = open("es_ES.po","w")
for line in fo:
if line.find("msgid") == 0:
cad = gtrans.translate("en","es",line.split("\"")[1])
#print line.encode("utf-8"),
fi.write(line.encode("utf-8"))
fi.write("msgstr \""+cad.rstrip().encode("utf-8")+"\"\n")
elif line.find("msgstr") == 0:
pass
else:
#print line.encode("utf-8"),
fi.write(line.encode("utf-8"))
fo.close()
fi.close()
Sé que Mancho hizo algo parecido en PHP. Apenas pueda lo enlazo.
Enlace al artículo de Mancho
 Hace un tiempo ya, más o menos un año, hice un post acerca de un trabajo práctico que habíamos realizado en la cátedra Administración de Recursos, donde contaba la primera parte del resultado de nuestra investigación e implementación. Milton por otra parte había realizado unos post ya acerca de lo que venía probando en la plataforma Mono en ese entonces.
Hace un tiempo ya, más o menos un año, hice un post acerca de un trabajo práctico que habíamos realizado en la cátedra Administración de Recursos, donde contaba la primera parte del resultado de nuestra investigación e implementación. Milton por otra parte había realizado unos post ya acerca de lo que venía probando en la plataforma Mono en ese entonces.
Fue a principios de año que decidimos que era una buena oportunidad, juntar todo lo que teníamos suelto de investigación, la implementación que habíamos hecho y presentar el trabajo como un artículo en el EST 2008, bajo el marco de las 37 JAIIO (Jornadas Argentinas de Informática e Investigación Operativa). Las mismas comenzaron el pasado 08 de septiembre y finalizaron ayer 12. Se realizaron en conjunto con el CLEI 2008, un gran evento latinoamericano que nuclea a muchos investigadores y gente de la industria informática de toda latinoamérica (incluso con algunos visitantes de otros lugares del mundo). Se presentaron más de 400 trabajos en total sumando todos los eventos. Se aprobaron unos 300 según comentaba una de las organizadoras en el cierre de estas conferencias, con una alta tasa de expositores que presentaron sus trabajos.
Bueno, volviendo al tema del EST, decidimos presentarlo. Además presentamos otro de que habíamos realizado en inteligencia artificial, donde utilizabamos Java y Prolog (hay un post al respecto también) para resolver el trabajo práctico.
La tarea de confeccionar el paper no fue sencilla. Debíamos apegarnos a un estándar de publicación de las LNCS. Nuestro trabajo fue realizado en LaTeX, con lo cual contabamos con una DocumentClass para utilizar, pero debíamos prestar suma atención a otras cuestiones.
El título del trabajo es el mismo de este post, Desarrollo de Software con Mono, una Implementación Libre de .NET, Multiplataforma e Independiente del Lenguaje. El título del otro trabajo presentado es Diseño de un Agente Basado en Objetivos que Utiliza Enfoques Basados en Búsqueda Informada, No Informada y Cálculo Situacional. Ambos fueron aceptados y tuvieron su exposición en la sesión de posters.
Fue una experiencia muy grata la de recibir a muchos compañeros y poder comentarles los resultados de nuestros trabajos. En la sesión de posters se vieron muchos trabajos, los cuales estaban dividos en dos categorías: trabajos finales y trabajos de cátedra. La verdad muchos muy interesantes, de los cuales recuerdo un trabajo final que me gustó, en cual utilizaba técnicas de minerías de datos y reglas de asociación para detectar «concerns» en un software. Luego podía detectar mediante la traza de ejecución los diferentes aspectos en el sistema.

Al finalizar la sesión de posters se anunciaría a los 3 preseleccionados de cada categoría para una sesión oral al otro día. Ese día se anunciaría a los ganadores del concurso. Creo que no había mencionado esta parte. El EST es un lugar donde los alumnos pueden exponer sus trabajos a modo de artículo y luego concursan por los 3 mejores de cada categoría (finales y de cátedra). Con Milton y César tuvimos la satisfacción de ser reconocidos con un segundo puesto en el orden de méritos en los trabajos ganadores del concurso :-D. Sinceramente había trabajos muy buenos, y la tarea de los evaluadores debe haber sido ardua!.
Los evaluadores recorrían la sesión sin indicar que eran evaluadores de una determinada área de incumbencia. Sin embargo, algunos observadores externos (mi viejo que se dio una vuelta) advirtieron el interés de ciertas personas las cuales nos hicieron explicarles cada detalle implementado e incluso aún no implementado en el trabajo.

Haber defendido tanto el trabajo me recordó las tardes y mañanas que le dedicamos a comprender los problemas presentados y de los cuales disfrutamos tanto.
Escribo todo esto para contar nuestra experiencia. Ahora es tarde, pero sigo entusiasmado con las jornadas y no quería dejar de escribir unas líneas. Seguramente pongo más fotos del evento luego, o hago otro post, pero quiero animar a nuestros pares a que participen de eventos de este estilo, ya que la experiencia adquirida es única.
Particularmente quiero expresar mi orgullo de superación personal y grupal que hemos tenido. Muchas veces habíamos incurrido en los mismos errores, de los cuales menciono algunos que recuerdo: transparencias llenas de texto, gran cantidad de las mismas (más de 30 a veces), charlas muy largas (dimos una de 40 minutos en administración gerencial). Incluso el poster el simposio tenía mucho texto!!!.

Sin embargo: La transparencia de la presentación en sesión oral tenía 16 slides, 13 efectivas (sacando el muchas gracias, agenda y tapa). Nos tomó menos de 15 minutos (se nos apagó el cañon) pero estábamos terminando. Jamás nos dominaron los nervios, ni creo que hayan existido: nos desenvolvimos con gran soltura. Seguro tenemos mucho que mejorar pero al menos estos tres aspectos los mejoramos en un año :-D.
Así que gracias Milton y César por haber podido compartir esta experiencia con ustedes. Gracias Daiana por el apoyo y compartir todo conmigo y ayudarme a revisar las cosas hasta el detalle. Y gracias flia… por todo :-).
Acá está el link al artículo, al poster y a las transparencias que utilizamos.
También hay un link al proyecto. Por cualquier duda por como compilarlo, nos consultan, aunque con MonoDevelop con IKVM.NET, VB.NET, Boo y las extensiones de Boo, Java para el IDE debería bastar.
Artículo: Desarrollo de Software con Mono, una Implementación Libre de .NET, Multiplataforma e Independiente del Lenguaje (Artículo)
Poster: Desarrollo de Software con Mono, una Implementación Libre de .NET, Multiplataforma e Independiente del Lenguaje (Poster)
Transparencias: Desarrollo de Software con Mono, una Implementación Libre de .NET, Multiplataforma e Independiente del Lenguaje (Presentaciones)
SVN: svn checkout http://admrec.googlecode.com/svn/trunk/src/ mono-read-only
Para la cátedra de Administración de Recursos el año pasado, debíamos realizar un trabajo de investigación y desarrollo, en el cuál se mostraran nuevas tecnologías que permitieran integrar sistemas. Buscando cumplir con el objetivo asignado por la cátedra y a la vez investigar en algo que aún no hubiéramos profundizado fue lo que nos llevó a la plataforma Mono.
Milton ya estaba desarrollando un sistema utilizando esta plataforma, César ya había programado con .Net (C# y VB.Net) para un TP anterior y yo algo de Web Services ya había utilizado (consumido con PHP, pero nunca creado) y además estaba usando C# para algunas cosas.
Sin embargo queríamos probar la madurez del proyecto Mono, utilizar las últimas versiones de MonoDevelop como IDE y las librerías y compiladores que pudieramos. Se nos ocurrió implementar un sistema de mensajería instantánea al estilo Gaim, obviamente que con la única posibilidad de enviar mensajes de texto y ver la lista de usuarios conectados. Pero, a medida que avanzabamos, le ibamos agregando cosas.
Este texto es la junta de varios post por separado que tenía en borrador y que decidí postearlos todos juntos. Creo que así es más sencillo de ubicar y poder agregar otros luego. Son algunas cosas que observé o hice cada vez que tuve algún tiempo con Smalltalk. Acá van 😛
Escondiendo el Transcript en Smalltalk Express
El Transcript que utilizamos para trabajar es un workspace. Este objeto viene por defecto «vivo» en el entorno de Smalltalk Express. Se lo puede cerrar enviándole el mensaje close al mismo (a través de la variable global Transcript).
El método «esconderTranscript» podría ser implementado en la ventana principal de la aplicación, para poder esconder el Transcript una vez que no lo necesitemos.
1
2
3
| esconderTranscript
Transcript close.
Transcript := nil. |
esconderTranscript
Transcript close.
Transcript := nil.
Lo que si, una vez cerrado, ¿cómo volvemos a abrirlo? ¿a quién le enviamos un mensaje? MDITranscript es la clase responsable de la inicialización del mismo. O sea, deberíamos tener alguna manera siempre de poder hacer un «do it» sobre alguna ventana para poder volver a mostrar el Transcript.
El método «mostrarTranscript» podría ser implementado en la ventana principal de la aplicación, para poder esconder el Transcript una vez que no lo necesitemos.
1
2
3
| mostrarTranscript
(Transcript = nil) ifFalse: [Transcript close.].
Transcript := MDITranscript initializeTranscript. |
mostrarTranscript
(Transcript = nil) ifFalse: [Transcript close.].
Transcript := MDITranscript initializeTranscript.
Serializando Objetos en Smalltalk
Con la clase ObjectFiler podemos guardar una representación binaria de nuestro objeto en un archivo en el disco. De esta manera, si nuestro objeto tiene referencias a otros objetos (haya ciclos o no), estos serán serializados también. Esto nos permitiría poder guardar los datos de nuestra aplicación en un archivo en vez de usar la imagen de Smalltalk. Por ejemplo el método guardar a continuación, está serializando el objeto referenciado por la variable Instancia.
1
2
| guardar
ObjectFiler dump: Instancia. |
guardar
ObjectFiler dump: Instancia.
Si queremos recuperarlo desde el disco, bastará con tener implementado algún método que utilice el ObjetFiler de la siguiente manera:
1
2
| cargar
Instancia := ObjectFiler load. |
cargar
Instancia := ObjectFiler load.
Aclaración: Para poder reconstruir el objeto es necesario que las clases que definen su estructura se encuentren cargadas en el entorno.
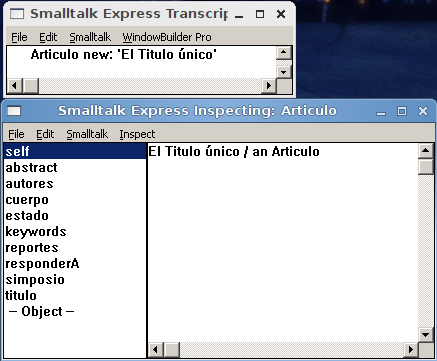
Cambiando la forma en que el Inspector nos ve en Smalltalk
Cuando hacemos un inspect de un objeto generalmente si tiene referencias a otros objetos vemos que la representación textual de estas referencias dice «anObjeto», «aSystem», «aTalCosa». Esto es además de un poco molesto, incómodo si se desea hacer un debug rápido y saber de que objeto se está hablando. Para esto, podemos reeimplementar en nuestra clase el método «printOnStream», que es el que se ejecuta cuando el objeto recibe el mensaje con el mismo nombre desde el Inspector. ¿Cómo lo reimplementamos? Le podemos agregar a esa salida algún valor clave que identifique a nuestro objeto, o lo que necesitemos ver en un inspect típico conservando quizá el a y an object agregados.
1
2
3
4
5
6
7
8
9
10
| printOn: aStream
"Agregaremos el DNI de la persona y delegaremos el
resto a la implementación de la clase Object"
| aString |
"aquí le pedimos el DNI y lo guardamos en aString.
Además le concateno una barra para separarlo luego
de la salida por defecto de la clase Object "
aString := (self getTitulo) , ' / '.
aStream nextPutAll: aString.
super printOn: aStream. |
printOn: aStream
"Agregaremos el DNI de la persona y delegaremos el
resto a la implementación de la clase Object"
| aString |
"aquí le pedimos el DNI y lo guardamos en aString.
Además le concateno una barra para separarlo luego
de la salida por defecto de la clase Object "
aString := (self getTitulo) , ' / '.
aStream nextPutAll: aString.
super printOn: aStream.
La implementación original en la clase Object:
1
2
3
4
5
6
7
8
9
10
11
12
| printOn: aStream
"Append the ASCII representation of the receiver
to aStream. This is the default implementation which
prints 'a' ('an') followed by the receiver class name."
| aString |
aString := self class name.
"debido a las reglas del inglés, si comienza con vocal se antepone 'an'
y sino 'a'. Ej anObject (en castellano sería unObjeto)"
(aString at: 1) isVowel
ifTrue: [aStream nextPutAll: 'an ']
ifFalse: [aStream nextPutAll: 'a '].
aStream nextPutAll: aString |
printOn: aStream
"Append the ASCII representation of the receiver
to aStream. This is the default implementation which
prints 'a' ('an') followed by the receiver class name."
| aString |
aString := self class name.
"debido a las reglas del inglés, si comienza con vocal se antepone 'an'
y sino 'a'. Ej anObject (en castellano sería unObjeto)"
(aString at: 1) isVowel
ifTrue: [aStream nextPutAll: 'an ']
ifFalse: [aStream nextPutAll: 'a '].
aStream nextPutAll: aString
Exportando/Importando clases de Smalltalk
Para exportar desde el Transcript una clase de Smalltalk, podemos usar la clase ClassReader. El método forClass, instancia un ClassReader para una determinada clase. Esto es, si tenemos una clase Persona, obtendremos la instancia con
1
| ClassReader forClass: Persona |
ClassReader forClass: Persona
A este objeto le podemos enviar el mensaje fileOutOn: file, donde file es una instancia de File.
Para esto, en un TP que implementamos hace un tiempo, creamos una clase ABackUp, para exportar de forma sencilla todas las clases de nuestro sistema en un solo archivo.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| Object subclass: #ABackUp
instanceVariableNames: ''
classVariableNames:
'LasClases '
poolDictionaries: '' !
!ABackUp class methods !
backup
| reader file |
ABackUp inicializar.
file := File newFile: 'export\backup.cls'.
LasClases do: [:c |
c fileOutOn: file.
file nextChunkPut: String new.
(ClassReader forClass: c class) fileOutOn: file.
(ClassReader forClass: c) fileOutOn: file ].
file close.!
inicializar
LasClases := OrderedCollection new.
" Carga de las clases a backupear "
LasClases
add: Articulo;
add: ArticuloDB;
add: ArticuloEstado. LasClases := (LasClases,ArticuloEstado allSubclasses).
LasClases
add: ComunidadCientificaDB;
add: Congreso;
add: CongresoDB;
add: PanelArbitros;
add: Persona;
add: Recibo;
add: Reporte;
add: Simposio;
add: SistemaCongreso;
add: Principal;
add: AsignarCalificacionJuez;
add: AsignarJuez;
add: CrearCongreso;
add: NuevoSimposio;
add: RanckingArticulos;
add: RegistrarAutor;
add: RegistrarJuez;
add: RegistrarPersona;
add: SubirArticulo;
add: Rol. LasClases := (LasClases,Rol allSubclasses).
LasClases add: ABackUp.!
new
^super new inicializar.! !
!ABackUp methods ! ! |
Object subclass: #ABackUp
instanceVariableNames: ''
classVariableNames:
'LasClases '
poolDictionaries: '' !
!ABackUp class methods !
backup
| reader file |
ABackUp inicializar.
file := File newFile: 'export\backup.cls'.
LasClases do: [:c |
c fileOutOn: file.
file nextChunkPut: String new.
(ClassReader forClass: c class) fileOutOn: file.
(ClassReader forClass: c) fileOutOn: file ].
file close.!
inicializar
LasClases := OrderedCollection new.
" Carga de las clases a backupear "
LasClases
add: Articulo;
add: ArticuloDB;
add: ArticuloEstado. LasClases := (LasClases,ArticuloEstado allSubclasses).
LasClases
add: ComunidadCientificaDB;
add: Congreso;
add: CongresoDB;
add: PanelArbitros;
add: Persona;
add: Recibo;
add: Reporte;
add: Simposio;
add: SistemaCongreso;
add: Principal;
add: AsignarCalificacionJuez;
add: AsignarJuez;
add: CrearCongreso;
add: NuevoSimposio;
add: RanckingArticulos;
add: RegistrarAutor;
add: RegistrarJuez;
add: RegistrarPersona;
add: SubirArticulo;
add: Rol. LasClases := (LasClases,Rol allSubclasses).
LasClases add: ABackUp.!
new
^super new inicializar.! !
!ABackUp methods ! !
Cada vez que creábamos una clase nueva la agregábamos en la implementación del método «inicializar». Se podría haber realizado de otra forma, algo más automático o dinámico, como ser las clases utilizadas, pero esta fue la solución más rápida.
Luego desde el Transcript, haciendo un «do it» sobre «ABackUp backup.», obtenemos una serialización de las mismas en un archivo de texto.
Esto es todo por ahora. Si alguno tiene algo que quiera aportar y quiera que agregue en este mini artículo, coméntelo o me lo manda por email que lo agrego. Nos vemos en el próximo. 🙂
Del trabajo práctico número 2 de Inteligencia Artificial, el cuál implementamos en Java el simulador y la inteligencia en SWI-Prolog usando JPL, surgieron varias cosas interesantes.
El modelar las reglas de inferencia y la base de conocimiento del Agente en Prolog, fue muy sencillo debido a que previamente habíamos hecho un buen diseño lógico de los axiomas de estado sucesor, reglas causales, etc. El mapeo de estas reglas formales a Prolog fue casi directo.
El Agente, era un Agente Pacman con un mundo estático, aleatorio, cerrado, parcialmente observable, con visión limitada a las celdas adyacentes (izquierda, derecha, arriba, abajo). Dado tal escenario, Pacman debía ir conociendo el mundo y aplicando sucesivas reglas de inferencia para saber como cumplir su objetivo realizando ciertas acciones. Pero nuestro agente pensaba las cosas dos veces antes de determinar una acción. Mejor dicho, pensaba demasiadas veces lo mismo 🙂 (detalles dentro del post).